gpt-oss - comparing with OG transformers
Hi, all I’m back with something interesting, so as I wake up on Aug 6th 2025 and open my eyes… something fun happened on Aug 5th 2025 night at 10PM-ish (IST), No she did not text me, she did actually a couple weeks back but, ik it was a ruse and idc about drunk selfish fucks anymore…so i listened to her and kept my composure and saw her being selfish and disrespect me again, it’s fine I’m better off like this stone cold and selfish again. I hope this drama is finally done but we never know, I’m def in a much better place back with my engine happily…more posts on razix resouces re-design next week.
So what happened then, that was soo worth a blog post? OpenAI has finally released their long awaiting gpt OSS model, long after GPT-2. So in the golden age of LLMs and as a outsider doing graphics I was curious what was sooo special about this superman model. I’ve only read the “Attention is all you need paper” so I wanted to compare how things changed from there, how are these blackboxes powered to these amazing things. Let’s take a comparitive dive shall we…? The first thing I did was go to this link and read this file quickly, or as Monica from silicon valley says “I’ve perused your file”.

Link: https://github.com/openai/gpt-oss/blob/main/gpt_oss/torch/model.py This is the actual model arch, forget the weights. This is what we will uncover in the blog post and try to compare against the OG paper.
After quickly “perusing” with the help of chat GPT the core arch isn’t all so different from the OG paper, it still has a MHA (multi-head attention block), a FFN, rotary embedding (similar to how LLama uses it) and pre-layer norm. So what is soo special? The oversimplified answer…? they’re built from a scaled‑up, re‑engineered version of that same decoder block. They use advanced pre-training and inference methods like COT (chain of thought).
OG arch
Okay there’s umar jamil and andrej kaparthy for that so I’ll just leave the high-level diagram here for now.
I’ll be doing ASCII diagrams for now do forgive me…And since these chat-like GPT llms are just Decoder only we only care about the decoder part for now.
OG Transformer
Layers: 6
Hidden Size: 512
Attention Heads: 8
Norm Style: Post‑Norm
Positional: Learned Absolute
+----------------------------------------+
| LayerNorm (post) |
| Masked Self‑Attention (8 heads) |
| + Cross‑Attention (encoder output) |
| + FFN 512→2048→512 (ReLU/GeLU) |
+----------------------------------------+
gpt-oss architecture
From the file (https://github.com/openai/gpt-oss/blob/main/gpt_oss/torch/model.py) I read this is what I could gather: forgive me if there are any mistakes please comment below or reach out to me on my Github: https://github.com/Pikachuxxxx/
GPT‑OSS 20B
Layers: 44
Hidden Size: 6144
Attention Heads: 64
Norm Style: Pre‑Norm
Positional: Rotary
+-------------------------------------------+
| LayerNorm (pre) |
| Masked Self‑Attention (Fused QKV,64h) |
| Rotary Pos Embed |
| MLP (6144→24576→6144, GELU) |
| Tied LM Head (uses Embedding transpose) |
+-------------------------------------------+
The new and cool things:
- Fused QKV instead of separate matrices
- Pre-Norm layer instead of post norm
- Rotary PE (just like LLama)
- Final layer Tied to embedding
og
In the classic Transformer paper (and early GPT implementations), you had two different linear layers. So when predicting the next token, the model takes the hidden state → passes it through another completely separate matrix (LM head) → softmax. This doubles up on parameters: one matrix to embed, another to predict.
oss-gpt
Instead of having two separate matrices, GPT-OSS ties them together; The output LM head is just the transpose of the embedding matrix. logits = hidden @ W_embeddingᵀ
So what makes it soo special?
- The sheer scale If you missed the model params, take a good look again, it’s huge.
- COT - Chain Of Thoughts - Clever training makes the foundation methods even better using autoregressive tokesn
- MOE - Mixture of Experts - instead of keeping all of the FFN in memory we beak it down into small k-cluster models that are seperately trained to predict well and choose the top K-expoerts (idk how they exactly borken donw on what params and whow they are choosen, I”m assuming the current context does play a role in choosing the experts!) Wow this is soo complex
So this shear scale and complex pre/post techniques is what makes the OG arch soo good with data.
Just so you’re not satisfied with the scale metrics here how we get 20B params on the new gpt-oss model vs OG model:
OG Model params:
Param count =
Token Embedding: vocab_size × hidden (50k × 512 = 25.6M)
Positional Embedding: max_len × hidden (512 × 512 = 0.26M)
Attention per layer: 2 × 4 × hidden * hidden (2 × 4 × 512² = 2.1M)
FFN per layer: 8 × hidden * hidden (8 × 512² = 2.1M)
Decoder stack: 6 × (2.1M + 2.1M) = 25.2M
LM Head (separate): hidden × vocab (512 × 50k = 25.6M)
Total = 77 M params
gpt-oss-20B params:
Param count = sum of:
Embedding: vocab_size × hidden (~50k × 6144 = 307M)
Attention per layer: 4 × (hidden * hidden) = 4 × (6144 * 6144) [6144 = MLP hidden layer size]
MLP per layer: 8 × (hidden * hidden) = 8 × (6144 x 6144)
Total layers: 44 heads × (Attn + MLP) + Embedding + Norms = ~20B
so 77M vs 20B params is a lot! and that combined with the large amoint of data that OpenAI might have allegedly scraped and these super smart training texhniques it’s how the magic happens.
Misc: Autoregression and Chain of Thought
Since it’s a auto regressive model, that takes in input while generation, giving a prompt on how to think or generate info before final answer helps a lot.
Auto-regression is where we do moving window like tokens on the input vs generated tokesn move the input window as we generate more inputs and pass it off everytime we want to generate a new token. Basic ally predict next token gived previous tokens: say you have tokens [T1, T2] -> predict T3 now in next iteration input becomes [T1, T2, T3].
You can read more about chain of thought in this amazing blog here: https://cookbook.openai.com/articles/gpt-oss/fine-tune-transfomers#prepare-the-dataset, look out for the section on prepare the dataset. Look at the Multilingual-thinking data set from hugging face this will give a good visual idea on COT works using autoregressive generation.
https://huggingface.co/datasets/HuggingFaceH4/Multilingual-Thinking
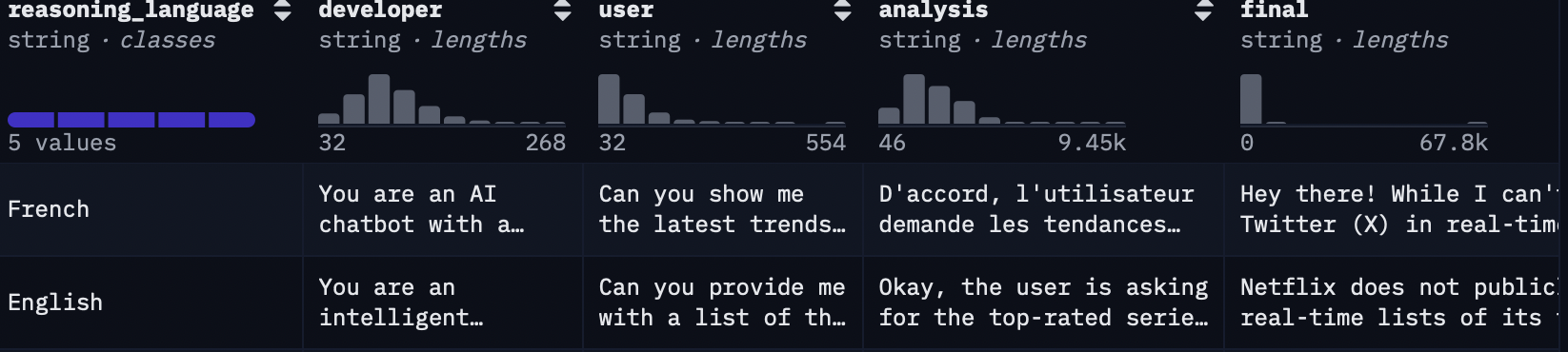
Kinda looks like interesitng prompt engineering during training phase itself? Interesting technique…
Closing notes
Ummm…finally reading about something made my heart race a bit. After a long time, I also made a game recently for GMTK 2025 and actually managed to finish it. It was fun. Life doesn’t excite my anymore but this does so ahh…idk let’s see what happens next for now just keep my head down and back to my engine for a few months until I finish the “asset is everything design” and start with the trippy game prologue.
Might try out gpt2-oss in rust for training my NPCs if it’s good enough…
Until then ciao! Byee…